На недавней конференции NVIDIA GTC 2026 компания Ли Авто | Li Auto представила революционную разработку – основу автопилота следующего поколения под названием MindVLA-o1. Этот прорыв, по словам основателя компании Ли Сяна, заключается в нативном 3D ViT¹, трехмерном визуальном кодировщике, который кардинально меняет подход к обучению искусственного интеллекта для вождения.
Революция в автопилотировании: новый подход Ли Авто | Li Auto

Как именно решили вопрос?
Ли Сян подчеркнул парадокс: люди учатся водить интуитивно, опираясь на раннее освоение пространственного мышления. В отличие от этого, современные системы автопилота, обучаясь на 2D-видео, имитируют человека, смотрящего записи, но не получившего реального опыта. Это приводит к ограничениям в понимании трехмерного пространства, что ранее было неразрешимой проблемой из-за колоссальных вычислительных требований.
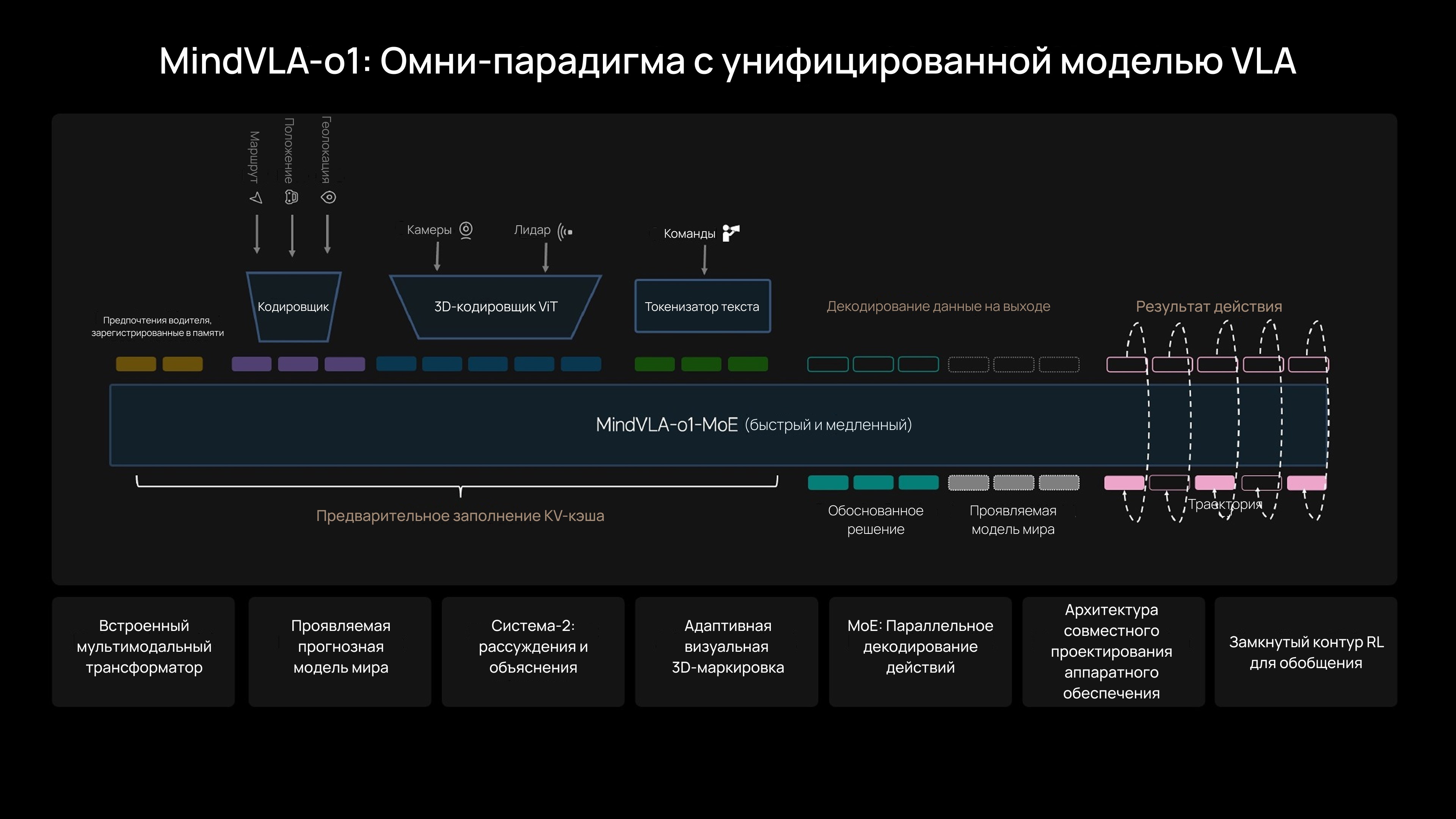
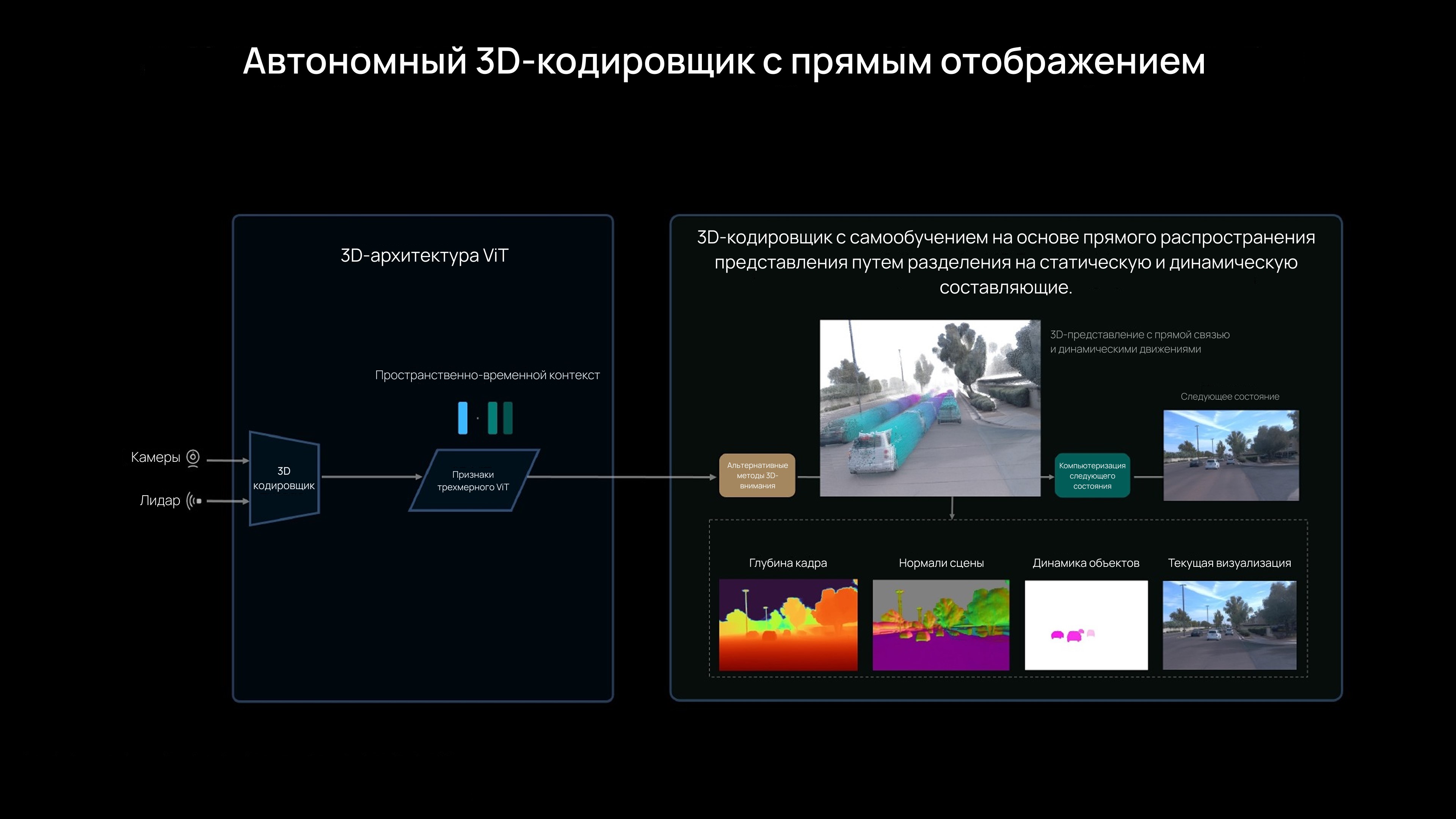
Новый 3D ViT¹ решает эту задачу, изначально работая в трехмерном домене, а не «восстанавливая» его из 2D. Модель обеспечивает унифицированное понимание 3D-геометрии и семантики, позволяя ИИ не просто видеть, но и осознавать мир вокруг. Роль лидара при этом трансформируется: из основного сенсора он становится инструментом калибровки.
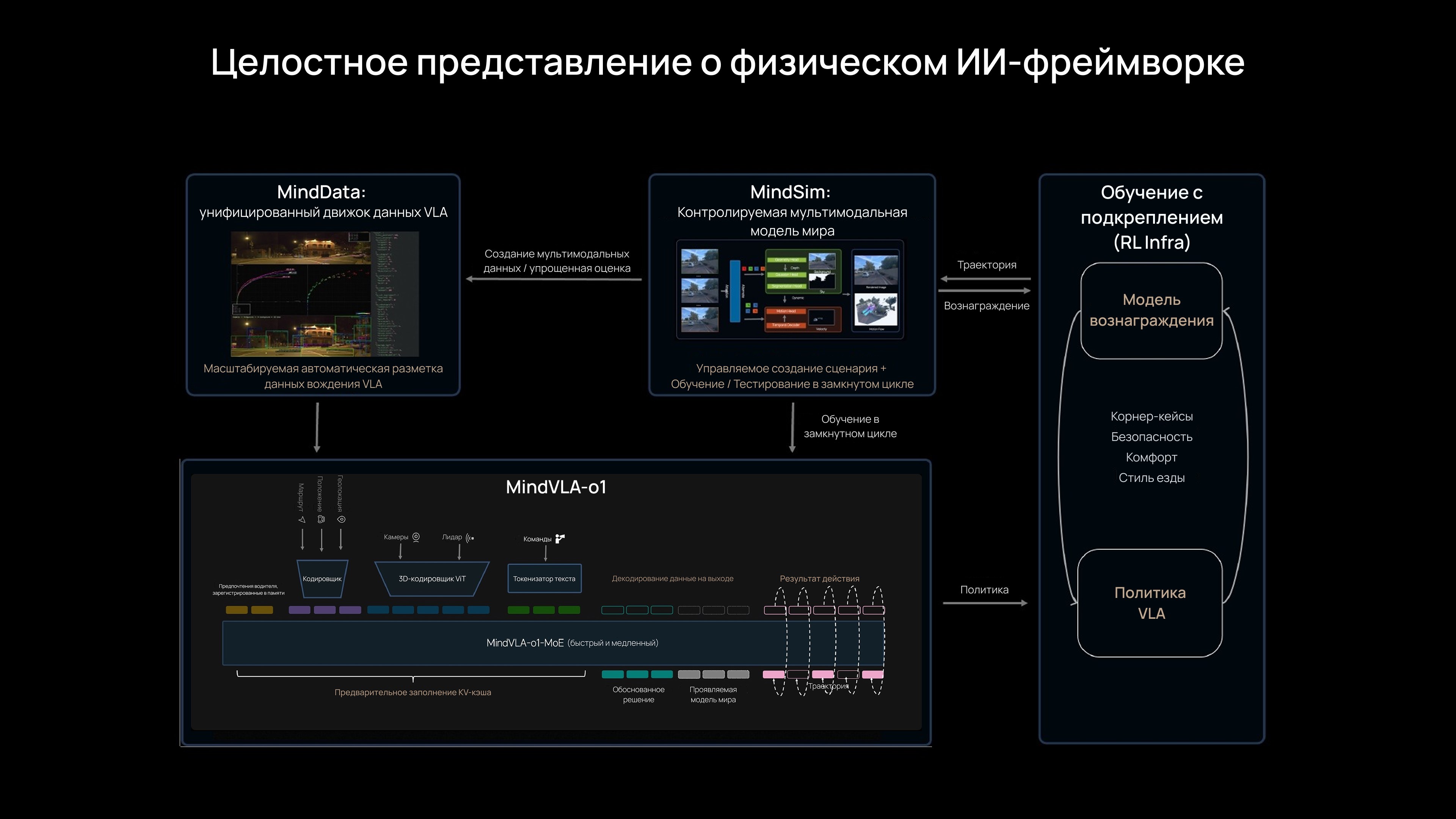
Ключевую роль сыграл чип собственной разработки Mach, обеспечивающий необходимую вычислительную мощность. MindVLA-o1, основанная на 3D ViT¹, объединяет пространственное понимание, мышление и манеру вождения в единой нейросети. Она способна не только анализировать текущую ситуацию, но и прогнозировать изменения сцены, демонстрируя «мультимодальное мышление».
Более того, эта универсальная база VLA² может применяться не только для автопилота, но и для управления роботами, открывая двери для создания универсальных физических ИИ-агентов. Автопилот становится лишь первым шагом в этом направлении.
Li Auto в наличии
Li Auto L6
Max R21

Выгода до 1 600 000 ₽
Ставка от 0,01%
Гарантия 3 года
Внедорожник 5 дв.
408 л.с.
Автомат
1496
Гибрид
Полный
Li Auto L6
Max color/R21

Выгода до 1 600 000 ₽
Ставка от 0,01%
Гарантия 3 года
Внедорожник 5 дв.
408 л.с.
Автомат
1496
Гибрид
Полный
Li Auto L7, I Рестайлинг
Ultra

Выгода до 1 400 000 ₽
Ставка от 0,01%
Гарантия 3 года
Внедорожник 5 дв.
449 л.с.
Автомат
1496
Гибрид
Полный
Li Auto L9, I Рестайлинг
Ultra

Выгода до 995 000 ₽
Ставка от 0,01%
Гарантия 3 года
Внедорожник 5 дв.
449 л.с.
Автомат
1496
Гибрид
Полный
Автосалон Li Auto
Li Auto
¹ 3D ViT – 3Д Визуальный трансформер / 3D Visual Transformer – архитектура нейросетей, которая воспринимает трехмерное изображение как последовательность слов. Она видит мир как голограмму, которую разобрал на миллиард мелких деталей и мгновенно понял, как они между собой связаны, чтобы не врезаться в угол стола или припарковать машину.
² VLA – Vision-Language-Action – модель «Зрение – Язык – Действие».
³ OCC – Occupancy prediction – это метод представления и предсказания окружающей среды в виде сетки трехмерных ячеек (вокселей), которая может быть или занята, или свободна, или в статусе «отсутствуют данные».